







In recent decades, thanks to advances in computing it has been possible to apply Deep Learning technologies to fields in which they were not previously viable.
Miguel Jiménez Gomis
Computer vision
In recent decades thanks to advances in computing it has been possible to apply Deep Learning technologies to fields in which they were not previously viable. In this post we are going to focus on the improvements that deep learning brings the capture of distance maps in scenes, a technology that applies to sectors as diverse as automotive, cinematography or medicine.
Basis of the technology
A deep learning network is a hierarchical graph of concepts, which allows a program to learn complex concepts from simple ones. It is one of the multiple Artificial Intelligence technologies that exist, and that fits very well to those problems in which a more abstract generalization has to be made about the space of possible solutions.
For deep learning programs to learn, one of the main approaches must be followed:
- Supervised Learning: A “valid” and labeled training dataset is defined on which the network will extract the concepts.
- Unsupervised learning: With an unlabeled dataset , the network is allowed to extract the knowledge that is most useful to solve the specified problem.
Deep Learning applied to Stereo matching
One of the main problems of traditional Stereo matching algorithms is that they tend to take time to give decent results, and although they can be accelerated, for situations in which measurements are required in real time, deep learning techniques surpass them thanks to their computing speed and, in many cases, in the quality of its outputs. Other problem that the Deep learning techniques improves, is the difference in light and colors, which can be overcome with the extraction of the context of the image.
To do this, networks must be relatively simple and able to extract disparity references from stereo images and, in general, to extract contextual information to improve the results of this disparity.
The biggest difficulty that these techniques have, as in most cases in Deep Learning applications, is the training dataset. These are usually scarce and imprecise, so it is necessary to devote a high effort to their analysis before starting the training and can limit their accuracy.
Among the many networks that exist to perform the task of depth map from stereo images, the following stand out:
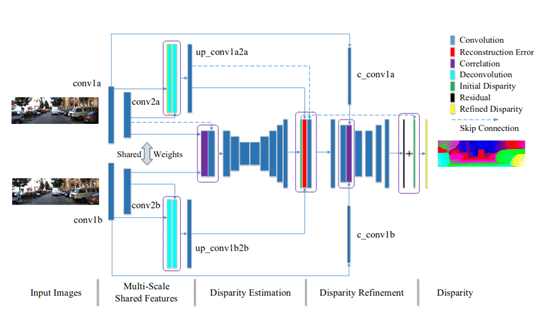
- IResNet (iterative residual prediction network), this network incorporates in its architecture all the necessary steps to perform a stereo matching in 1 single graph of computing through the use of convolutional networks: It detects the Shared Features And generates a Timing of Disparity, this is then refined by weighting the detected features and thus generating the final result.
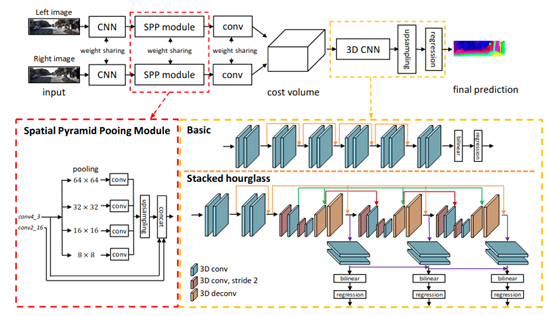
- PSMN (Pyramid Stereo Matching Network). Similar to the previous one, this network performs the steps to generate the stereo matching but takes advantage of cascading pooling convolutional pyramids to extract more information from the scenes making use of a deeper network.
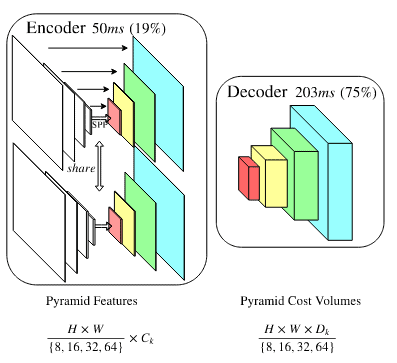
- Hierarchical Deep Stereo Matching (HDSM). It is a simple network to reduce memory consumption and execution time by using an encoder-decoder that through convolutions and convolutional pyramids, is able to obtain very good results.
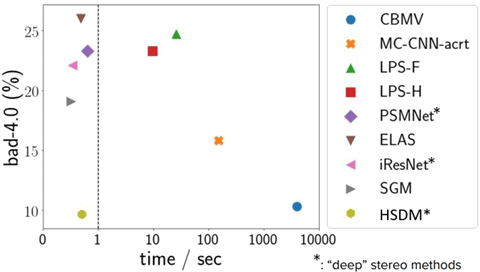
To compare these networks, it is possible to evaluate the accuracy of their results against the time they require for their execution. In the paper Hierarchical Deep Stereo Matching on High-resolution Images (Gengshan Yang et. al.) we are offered a comparison of the main methods of neural networks and the traditional computational ones:
Even with this, networks continue to present certain artifacts derived from occlusions in images and in the problems derived from the use of neural networks, one of those that can be seen in the following example of an output of the HDSM where the network doesn’t provide information in the areas with uncertainty:


These three networks are among the ones that generate the best results, but they are not the only ones that exist. Many research teams are continuously making developments to improve results and to be able to continue advancing in such an exciting field as computer vision .
At Wooptix we work to improve and integrate these technologies in the different solutions we offer, as well as other lines of research to take distance measurements in more complex situations through deep learning techniques and traditional algorithms.